이번 글은 서론이 불필요하게 깁니다. 본론은 아래 “MVCC internals” 부터 시작하니 필요한 내용만 보시려면 앞 부분은 넘겨주세요.
우리는 대부분 ‘트랜잭션’ 이라는 단어가 무엇을 의미하는지 안다. 이는 ‘애플리케이션에서 몇 개의 읽기와 쓰기를 하나의 논리적 단위로 묶은 것’ 으로, 프로그래밍 모델을 단순화하려는 목적으로 만든 것이다. 이걸 사용함으로써 우리는 운영중 발생하는 여러가지 문제를 원천에서 차단할 수 있다.
그리고 트랜잭션에는 아래처럼 ‘격리 단계’ 라는 개념도 있었다.
원칙적으로 트랜잭션은 동시성이 없는 것 처럼 행동할 수 있어야 하나, 이는 비용이 너무 크기에 꼭 필요한 경우에만 사용하기로 하고 일반적인 경우엔 이보다 격리성이 다소 완화된 트랜잭션을 사용하기로 했다.

여기서 말하는 ‘완화된 격리성’은 그 정도에 따라 일반적으로 위처럼 4단계로 나눈다. (각 단계에 대한 자세한 설명은 다른 글을 참고하자.) 이번 글에선 위 단계 중 Repeatable Read 에 주목한다.
Repeatable Read 란 이름 그대로 ‘반복적인 읽기’를 보장하는 격리 수준이다. 다른 트랜잭션이 데이터를 변경하고 커밋을 하더라도 현재 트랜잭션에선 그 변경분을 볼 수 없다. (Read Committed 수준에선 다른 트랜잭션이 커밋하면 변경분을 즉시 볼 수 있다.)
“다른 트랜잭션이 커밋을 했다 한들 현재 트랜잭션에서는 볼 수 없다.” 이게 어떻게 가능한걸까?
Snapshot Isolation (= MVCC)
간단히 설명하면, 트랜잭션이 특정 시점에 고정된 DB 의 일관된 snapshot 을 보도록 했다. “readers never block writers, and writers never block readers” 를 RDB 에서 어떻게 구현할 것이냐? 에 대한 명확한 해답이다.
조금 더 자세히는 객체가 커밋될 때 마다 해당 시점의 스냅샷을 생성하여 유지하는 것이다. 객체의 여러 버전을 만들어서 관리하므로 조금 있어보이게 MVCC(multi-version concurrency control, MVCC) 라는 이름을 붙였다.
Read Committed 수준에선 쿼리 수행 마다 스냅샷을 생성하고, Repeatable Read(혹은 Serializable) 수준에선 트랜잭션의 시작 시점마다 스냅샷을 생성한다. 사실상 격리 수준은 스냅샷의 생성 빈도에 따라 결정된다고도 볼 수 있다.

Snapshot 이란게 대체 뭘까
보통은 여기까지만 알아도 충분하다. 우리는 Read Commited 와 Repeatable Read 라는 두 가지 격리 수준의 차이에 대해 명확히 알고 있고, Repeatable Read 수준에서 DB 의 같은 row 에 대해 어떻게 트랜잭션 별로 다른 시점의 데이터를 볼 수 있게 했는지도 대충은 알고있다. 이번 글에선 여기서 조금만 더 들어가보자.
그래서 snapshot 이란게 대체 뭘까? MVCC 의 핵심처럼 보이는 이 snapshot 의 실제 형체가 궁금하다.
처음엔 단순히 DB 에서 테이블의 각 row 데이터를 트랜잭션 갯수 만큼 복사하여 저장해놓는 것일까 했다. 트랜잭션별로 다른 시점의 복사본을 보여주면 되는 것이니까 말이다. 물론 이렇게 구현하는 것도 방법일 수 있겠으나 너무 비효율적이다. 보통의 엔터프라이즈 애플리케이션은 단위 시간당 트랜잭션이 수백개일 것이고 그럼 row 별로 수십, 수백개의 복사본을 유지해야하는데 이러면 DB 의 비용도 수십, 수백배가 되는 것이다. 내 머리에서 나온 이런 똥같은 방식으로 MVCC 를 구현할 순 없다.
이 글에선 PostgreSQL(이하 PG) 이 MVCC 를 내부적으로 어떻게 구현했는지 알아보자. 앞으로 적을 설명은 PG 의 핵심 개발자 중 한명인 Bruce Momjian 의 MVCC Unmasked(pdf, PGConf 2024) 를 바탕으로 작성했다. 다른 RDB 도 방식은 거의 동일하다고 하니 이 방식을 표준이라고 생각해도 무방할 듯 하다.
MVCC internals
한줄 요약하면 스냅샷은 단순히 ‘메모리에 저장되는 트랜잭션 별 특정 시점의 환경에 대한 메타정보’ 라고 볼 수 있다. (데이터를 트랜잭션 수 만큼 그대로 복사해놓는 방식이 아니다!) 이 스냅샷 데이터는 아주 단순하고 가벼워서 수백 개, 수천 개를 생성해놓아도 부담이 없다. 어떻게 생겼는지 직접 DB 에 쿼리해서 확인해보자. PG 기준으로 현재 트랜잭션의 스냅샷은 pg_current_snapshot() 함수로 확인할 수 있다.
SELECT pg_current_snapshot();
-- 16472:16477:16472,16473,16474이 숫자들이 대체 뭔가 싶다. 하나하나 살펴보자.
: 를 기준으로 앞에서부터 ‘스냅샷의 xmin’, ‘스냅샷의 xmax’, ‘스냅샷의 활성 트랜잭션 ID 목록’ 이다. (xmin:xmax:xip_list)
xmin: 현재 시점 가장 오래된 활성 트랜잭션 IDxmax: 다음에 할당될 트랜잭션 IDxip_list: 현재 시점 활성 트랜잭션 ID 목록
이들 각각을 확인할 수 있는 함수도 있다. pg_current_snapshot() 는 아래 함수 3개의 묶음이다.
(pg_snapshot_xmin() + pg_snapshot_xmax() + pg_snapshot_xip())
딱 이 정도의 가벼운 정보를 트랜잭션의 생성 시점마다 생성하고, 이 정보를 토대로 어떤 데이터는 볼 수 있고 어떤 데이터는 볼 수 없는지 결정하는 것이다. 앞서 말했듯 Read Committed 의 경우 이 스냅샷 정보를 상대적으로 높은 격리 수준 보단 자주 생성한다.
그리고 위 같은 트랜잭션의 스냅샷과 더불어 DB 의 각 row 도 우리가 평소에는 보지 못하도록 숨겨놓은 데이터가 있다. 아래처럼 테이블을 생성하고 값을 저장했다고 해보자.
create table todo
(
id bigserial
constraint todo_pk
primary key,
content text,
status text
);
select *
from todo
where id = 0;
-- 쿼리 결과
0,응애,COMPLETED테이블 스키마 상으로는 칼럼이 3개밖에 없지만 사실 우리눈에 안보이는 정보들이 많이 숨겨져있다. 가령 select 문에 * 와 더불어 xmin, xmax 같은 정보를 추가로 불러올 수 있다. (그 밖에도 cmin, cmax, ctid 등등 많은 정보가 숨겨져있다. 우선 스냅숏 격리의 구현에서 제일 핵심적인 두가지 필드만 살펴보자)
select xmin, xmax, *
from todo
where id = 0;
-- 결과
1,0,0,응애,COMPLETED여기서 xmin, xmax 의 의미는 앞서 설명한 트랜잭션 스냅샷의 그것과는 의미가 다르다!
xmin 이란, 해당 row 를 만든 트랜잭션의 ID(이하 txId) 를 말하고 xmax 란, 해당 row 를 삭제했거나(DELETE) 또는 업데이트한(UPDATE) txId 를 말한다.
visibility check
이제 스냅샷 데이터가 어떻게 생겨먹었는지는 확인했다. 이제 이걸 어떤 방식으로 활용해서 트랜잭션별 격리를 구현했다는 말일까? 쿼리를 실행하면서 직접 확인해보기에 앞서 Momjian 선생님의 설명부터 듣고 가자.
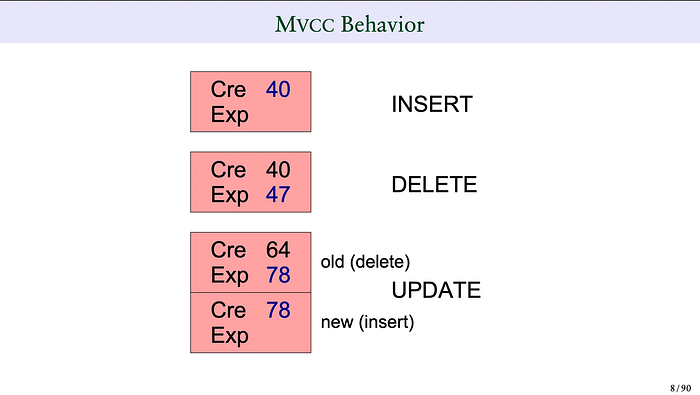
위 그림에서 빨간 박스는 특정 row 의 스냅샷 데이터이고 Cre 는 xmin, Exp 는 xmax 로 이해하면 된다. 박스 별 의미는 아래와 같다.
- 첫번째: [Cre 40, Exp X] txId 40 이 row 를 생성했다.
- 두번째: [Cre 40, Exp 47] txId 40 이 row 를 생성했고 그걸 txId 47 이 삭제했다.
- 세번째: [Cre 64, Exp 78][Cre 78, Exp X] txId 64 가 row 를 생성했고 txId 78 이 update 했다.
- 이 시점에 DB 를 조회했을 때 당연히 [Cre 78, Exp X] 데이터만 조회된다. 하지만 변경되기 전 데이터가 [Cre 64, Exp 78] 라는 형태로 안보이는 곳에 남아있다. (중요!)
위 그림을 이해했다면 이를 응용하여 트랜잭션 별로 visibility 를 어떻게 결정하는지 그 로직을 간단히 살펴보자.
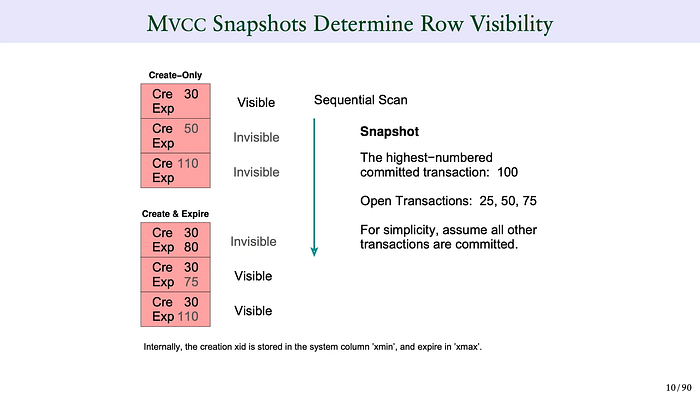
현재 트랜잭션의 스냅샷 데이터는 아래와 같다. (앞서 잠깐 봤던 xmin:xmax:xip_list 와 동일한 의미이다.)
- 현재 트랜잭션 시점으로 커밋된 가장 높은 txId 는 100
- 아직 열려있는(활성화된) txId 는 25,50,75
이런 상황을 가정하고 빨간 박스 여섯개의 visibility 를 결정해보자.
- 첫번째: [Cre 30, Exp X] Cre 가 낮으므로 볼 수 있다.
- 두번째: [Cre 50, Exp X] Cre 가 낮지만 현재 열려있는 txId 이므로 볼 수 없다.
- 세번째: [Cre 110, Exp X] Cre 가 높으므로 볼 수 없다.
- 네번째: [Cre 30, Exp 80] Exp 가 낮으므로 볼 수 없다.
- txId 80 이 변경 처리한 스냅샷이다. 낮은 txId 가 이미 변경했다는 의미이므로 해당 데이터는 현재 시점에서 유효하지 않다. - 다섯번째: [Cre 30, Exp 75] Exp 가 낮으나 현재 열려있는 트랜잭션이다. 볼 수 있다.
- 여섯번째: [Cre 30, Exp 110] Exp 가 높으므로 볼 수 있다.
- txId 110 이 변경 처리한 스냅샷이다. 높은 txId 가 변경했다는 의미이므로 해당 데이터는 현재 시점에서 유효하다.
간단한 PPT 한장이지만 그 의미를 장황하게 풀어서 설명해보았다. 실제 PG 내부 visibility 결정 로직은 이보다 훨씬 복잡하겠으나 이 글에선 이정도만 짚고 넘어가자. 더 깊이 알고싶다면 PGConf 2024 영상을 끝까지 시청하는 것이 도움이 되겠다.
이제 우리는 트랜잭션 별로 작고 간단한 스냅샷 데이터(xmin:xmax:xip_list)가 생성된다는 것을 알았다. 그리고 DB 는 각 row 에도 xmin 과 xmax 데이터를 저장하고 각 트랜잭션은 자신의 스냅샷 데이터를 토대로 xmin 과 xmax 값을 비교해가며 어떤 시점의 데이터를 가져와야할 지 안다는 것도 배웠다.
이제 실제로 PG 에서 쿼리해가며 위 설명처럼 동작하는지 눈으로 살펴보자. 앞서 만들어뒀던 간단한 데이터를 다시 가져왔다.
select xmin, xmax, *
from todo
where id = 0;
-- 결과
1,0,0,응애,COMPLETEDRepeatable Read 수준 트랜잭션을 2개 만들어서 한 트랜잭션에서 update 후 다른 트랜잭션에서 xmin, xmax 정보를 불러와보자.
select txid_current();
-- txid: 2
-- update 수행
update todo
set content = '응애2'
where id = 0;
select txid_current();
-- txid: 3
select xmin, xmax, *
from todo
where id = 0;
-- 1,2,0,응애,COMPLETED여기서 txId 2 트랜잭션을 커밋 후 새로운 트랜잭션(txId 4)을 생성하여 select 를 수행하면, 아래와 같은 결과를 볼 수 있다.
select txid_current();
-- txid: 4
select xmin, xmax, *
from todo
where id = 0;
-- 2,0,0,응애2,COMPLETED각 트랜잭션은 Repeatable Read 수준이기에 txId 3 이 커밋한 데이터를 txId 2 는 보지 못하고 있다. 그리고 각 시점에서 해당 row 의 xmin, xmax 값을 확인해보면 위에서 우리가 배웠던 것 처럼 동작하는걸 볼 수 있다.
우리가 RDB(PG) 에서 특정 row 를 수정하고 UPDATE 하면 겉으로 볼 때는 해당 row 가 바뀐 것 같지만 사실은 그렇지 않다. 기존 row 와 더불어 새로운 row 를 생성하고 xmin 과 xmax 값만 추가로 기록 해두는 것이다. (이를 구분하기 쉽게 tuple 이라 부르자)
그럼 여기서 중요한 것은 어떤 tuple 을 어떤 트랜잭션에게 보여지게 할 것이며 또 어떤 트랜잭션에게 안보이게 할 것이가? 인데 이게 앞서 빨간 박스로 설명했던 visibility 로직이다.
각 트랜잭션은 스냅샷에 기록된 xmin, xmax, xip_list 정보를 토대로 DB 에 수없이 많이 쌓여있을 tuple 들 중 트랜잭션의 Isolation 을 지킬 수 있는 알맞은 시점의 tuple 을 가져오는 것이다.
개인적으로 RDB 의 트랜잭션과 격리 단계에 관해 공부하면서 MVCC 라는 개념에 오해를 하고있었다. (무지에서 비롯된 오해..) 운이 좋게 좋은 영상과 자료를 찾아 그 오해를 풀 수 있었고, 바르게 이해한 내용을 글로 간단히 적어보았다. 부족한 글이지만 MVCC 의 내부 동작을 이해하는 데에 도움이 되었으면 좋겠고 나아가 더 깊이 공부하고자 하는 의지를 북돋울 수 있었다면 더할 나위 없이 기쁠 것 같다.
Reference